
Frontend System Design of Google Docs (High-Level Design)
A Comprehensive Look at Designing an Interactive, Secure, and Scalable Document Editing Experience

1. Introduction
1.1 Overview of Google Docs
Google Docs is a web-based word processing application that allows multiple users to create, edit, and collaborate on documents in real time. Unlike traditional desktop word processors, Google Docs operates entirely in a web browser and stores documents in the cloud. This means that any changes made by one user can instantly appear for other users, enabling seamless collaboration without the need for constant saving and reloading.
When we type text in Google Docs, we see our changes immediately on the screen. If someone else is editing the same document, we can watch their edits appear almost instantly. This happens because the application uses real-time synchronization to update everyone’s view of the document. Besides just typing text, Google Docs also supports formatting (like bold and italics), inserting images, creating tables, commenting, and many other advanced features.
The beauty of this approach is that we never lose our work—Google Docs continuously saves all our changes. This makes it easy for multiple people to work together on a single document without worrying about merging different versions or emailing documents back and forth. The web-based nature of Google Docs also allows it to run on any device with a modern web browser, including laptops, tablets, and smartphones.
1.2 Why is Google Docs a Challenging Frontend System?
Building an application like Google Docs presents unique challenges, especially on the frontend. Traditional word processors can store and manipulate documents locally, where changes are handled by the software running on a user’s computer. However, Google Docs has to handle these operations in a web environment and deal with multiple people editing the same document at the same time.
Here are some reasons why it’s challenging:
Real-Time Collaboration: The system must constantly update the document view for all users. If three people are typing in three different parts of the document, everyone should see those updates instantly. This requires a sophisticated mechanism to synchronize changes without losing any user’s edits.
Complex Document Structures: Besides plain text, Google Docs supports tables, images, headers, footers, and many other formatting options. Handling all these features in a browser-based environment, while keeping the application responsive, is complex. Each feature (like bold formatting or inserting a table) needs to be carefully managed so it works in real time for all collaborators.
Version Control and Conflict Resolution: If two people type in the same spot at the same time, the system must decide whose changes go first or how to merge them. This is not straightforward and often involves algorithms like Operational Transformation (OT) or Conflict-free Replicated Data Types (CRDTs).
Performance at Scale: Google Docs needs to handle huge documents with many pages and still remain fast. When we scroll through a large document, the application must display content quickly without freezing or causing long delays. Achieving this smooth performance takes careful optimization and sometimes specialized data structures.
Network Issues and Offline Support: Users might lose their internet connection or switch to a weaker network. The application must handle this gracefully, allowing them to continue editing offline and then synchronize changes once their connection is restored.
All these factors make the Google Docs frontend complex. It needs to be more than just a simple text editor. It has to function as a real-time collaboration tool that runs smoothly for millions of people around the world.
1.3 Key Objectives of This Design
When designing a frontend system for a Google Docs–like application, we focus on a few main goals:
Real-Time Collaboration: Ensuring that changes made by any user are quickly reflected for all other users is essential. This means we need a stable and efficient way to communicate document updates between browsers and the server.
Ease of Use and Intuitive Interface: The system should be easy for anyone to pick up and use. Text formatting, inserting images, and adding comments should all be straightforward tasks. Even advanced features like suggestion mode or track changes should be accessible without requiring deep technical knowledge.
Robustness and Reliability: Users expect their work to be saved automatically and never lost. The design should handle unexpected problems like a user’s browser crashing or a temporary network loss without losing edits. A robust system might store changes locally first, then sync them once the connection is stable.
High Performance and Scalability: The application should remain responsive even for large documents and many concurrent users. A slow, laggy editor can disrupt collaboration and frustrate users. Techniques like lazy loading or virtual scrolling can help maintain speed when documents become lengthy.
Security and Access Control: Confidential information may be stored in these documents, so the system must protect data at all times. This includes validating user permissions, preventing unauthorized access, and ensuring that malicious scripts cannot be injected into documents.
Extensibility and Feature-Rich Environment: Users often demand additional features, such as chat within the document, version history, and commenting. The design should be flexible enough to incorporate these features without major rewrites or architectural changes. This makes it easier to evolve the application over time.
By keeping these objectives in mind, we ensure that our system can offer a seamless user experience, support real-time collaboration, and remain secure and reliable. In the following sections, we will explore how to achieve these goals by diving deeper into the technical details of designing a frontend system that can power an application like Google Docs.
2. System Overview & Requirements
Designing the frontend of a system like Google Docs requires a clear understanding of what the application must do (functional requirements) and how well it must perform under various conditions (non-functional requirements).
2.1 Functional and Non-Functional Requirements
Functional Requirements are the core actions and behaviors the system must be able to perform. For an online text editor like Google Docs, these might include creating new documents, editing text (including rich formatting like bold or italics), inserting images or tables, sharing documents with others, and allowing multiple people to edit at the same time. A good way to think about functional requirements is to consider any activity a user must be able to complete, such as typing text, undoing and redoing changes, or seeing other people’s cursor positions in real time.
Beyond text editing, we also want the ability to store and retrieve documents. For instance, users should be able to open existing documents from the server or their local cache, make changes, and save these changes so they are not lost. Another key function is the commenting feature, where users can leave feedback in the document margins, and track changes, which enables suggestion mode. We might also include export functionalities, like exporting to PDF or Word format.
Non-Functional Requirements focus on qualities like performance, security, and usability. For performance, the system should remain responsive even when documents grow large or when many users are editing simultaneously. Security requirements involve ensuring only authorized users can access documents, and that sensitive data is protected from attacks (like Cross-Site Scripting). Usability requirements focus on simplicity and consistency in the user interface, making it easy for beginners to discover editing tools and for advanced users to utilize shortcuts. Reliability is another key aspect: the system should handle unexpected disconnections gracefully and preserve user data whenever possible.
2.2 Defining the Scope: Supporting File Types & Features
One of the first decisions in designing something like Google Docs is to define its scope clearly. In other words, we need to decide what kinds of documents we will support and to what extent we will support them.
Some applications allow us to create and edit only plain text files, which is simpler but limits us to basic editing features. Others, like Google Docs, can handle a variety of file types, including .docx and .pdf, and support advanced features like images, tables, footnotes, comments, and more. When we open the scope to multiple file types, we introduce additional complexity in parsing, rendering, and editing those formats.
To keep the design manageable, we might start by focusing on core text features—like bold, italics, and headings—and gradually add advanced elements such as collaborative editing, inserting images, and track changes. The more features we include, the more we have to plan for performance optimization (especially as documents grow large) and handle specialized data structures (like complex table layouts or embedded media).
2.3 Key Features of Google Docs
The main purpose of Google Docs is to allow multiple users to work on the same document at the same time in a user-friendly interface. Some of the most prominent features include:
Real-Time Collaboration: Users see each other’s changes as they happen, along with indicators like cursors or selection highlights for each collaborator.
Rich Text Editing: This covers basic and advanced formatting options, such as changing fonts, inserting bullet lists, adding headings, or styling text with bold, italics, and underline.
Document Sharing & Permissions: Documents can be shared with individuals or groups, with varying levels of access such as view-only, comment-only, or full editing rights.
Commenting & Suggestion Mode: Users can leave inline comments, reply to them, and suggest edits that the document owner can either accept or reject.
Autosave & Version History: Changes are saved automatically, and users can revisit or restore previous versions of the document.
These features guide many of the architectural decisions we will make on the frontend, such as how to structure the user interface and how to handle real-time data updates.
2.4 Handling Real-Time Collaboration
Real-time collaboration means that if one user types or deletes something, every other user viewing the same document should see that update nearly instantly. This involves continuously sending updates from the user’s browser to a backend server and receiving updates from other collaborators.
On the frontend, we need a way to capture changes quickly—often on every keystroke—and then merge or apply them to the visible document. To do this, we typically rely on technologies like WebSockets or a similar real-time communication protocol rather than simple HTTP requests because HTTP polling can introduce noticeable delays.
When two or more people type in the same part of the document, we need a conflict resolution approach. One common approach is using algorithms like Operational Transformations (OT) or Conflict-free Replicated Data Types (CRDTs), which are designed to handle concurrent edits in ways that preserve each user’s intent.
Beyond the core text, real-time collaboration also applies to features like simultaneous commenting or dynamic updates to images and tables. The frontend must manage all this data in a way that remains consistent across all user sessions, even when the edits happen at the same moment.
2.5 Challenges in Designing a Frontend-Heavy Application
A “frontend-heavy” or “client-heavy” application places much of the processing and logic in the user’s browser rather than on a central server. This can be advantageous for responsiveness and speed, but it also brings several challenges:
Performance and Rendering: As documents get larger (hundreds of pages or thousands of elements), rendering them and handling edits in real time can become slow if we do not optimize. The frontend must manage memory usage carefully and render only what the user needs to see at any moment.
State Management Complexity: Keeping track of every user’s edits and the application’s overall state (like cursor positions, highlights, and comments) is complicated. When multiple people are editing, state changes can happen in rapid succession, so we need a robust structure (like Redux or other libraries) to avoid data conflicts and ensure the UI reflects the latest updates.
Offline Support: If a user loses their internet connection, we still want them to be able to type and store changes locally, then sync those changes when they come back online. Managing this on the client side requires additional logic to detect offline status, queue changes, and handle possible conflicts when reconnecting.
Security in the Browser: The browser is exposed to potential security threats like malicious scripts or attempts to modify local data structures. We have to ensure our code can handle untrusted inputs without compromising users’ data or system integrity.
Integration with Multiple Services: Often, Google Docs-like applications need to integrate with other services (like cloud storage, identity providers, or third-party plugins). This means the frontend must be prepared to handle different types of data, authentication flows, and user interface components in a cohesive way.
While these challenges are significant, modern frameworks, libraries, and best practices can help us tackle them effectively. By carefully planning our architecture, choosing suitable data structures, and testing our application’s performance under realistic conditions, we can build a highly interactive, robust, and user-friendly real-time editor that runs smoothly in the browser.
3. High-Level Architecture
3.1 Overview of the Frontend Architecture
When building a complex, real-time application like Google Docs, we need to consider how our code is structured so that it’s scalable, maintainable, and efficient. The frontend architecture typically consists of three main layers:
UI Layer (Presentation): This includes all the visual components that a user interacts with—think buttons, text fields, toolbars, and the document editor area.
State Management Layer: This manages data or “state” that different parts of the application need to access or modify, such as the current document content, user collaboration sessions, and editing settings (font sizes, color themes, etc.).
API/Network Communication Layer: This handles sending and receiving data from the server, like saving changes to the backend, loading documents, and managing collaboration events.
By separating these layers, it becomes easier to change one part without breaking another. For instance, if we decide to swap out our state management library, we don’t have to rewrite all our UI components.
3.2 Framework and Library Selection
Choosing a suitable JavaScript framework (or library) and supporting tools is crucial. Below are a few considerations:
React: A popular library for building user interfaces based on components. React’s virtual DOM and component-based architecture make it easier to break down complex UIs into smaller, reusable parts.
Vue or Angular: These are also good options, but React is often favored for large, collaborative projects due to its ecosystem of libraries and community support.
Real-Time Libraries: If we need real-time communications, we could use something like Socket.IO or integrate with any environment supporting WebSockets.
Why React?
React has a rich set of third-party libraries (for text editing, state management, etc.).
It has a strong community and many established patterns for solving common problems like collaboration and real-time updates.
React’s concept of components makes it simpler to create a modular, maintainable architecture where each piece of the UI can be worked on independently.
3.3 Component Hierarchy & UI Layer Design
A component hierarchy describes how we organize our React components into a tree-like structure. Below is an example of how we might structure a Google Docs–style editor:
App Component (Root)
Responsible for rendering the core layout, such as the navigation bar, side menu, and the main editing area.
EditorPage Component
Contains the editor itself and some additional UI elements like a toolbar (bold, italic, underline buttons, etc.).
Toolbar Component
Holds formatting buttons, font controls, and other document-related actions (saving, undo, redo).
DocumentEditor Component
The core text-editing surface. This might wrap a rich text editor library (e.g., Draft.js, Quill, ProseMirror) or a custom-built solution.
CollaborationTools Component
Manages user presence indicators, cursors, or chat if we have real-time chatting.
Key Goals When Designing the Component Hierarchy:
Reusability: Make each component do one thing well, so we can reuse it in other parts of the app (e.g., using the same Toolbar in multiple pages).
Maintainability: Keep components small and focused. A giant, monolithic component is harder to test and update.
Scalability: As the app grows, a well-organized component structure will make it easier to add new features without rewriting existing code.
3.4 State Management Strategy (Redux, Zustand, or Custom Solution)
In a real-time editing application, we have to deal with frequent state updates. For instance, user A types a word, user B types a word, user A changes formatting, and so on. Here are some common state management approaches:
Redux: A popular library that enforces a unidirectional data flow (actions → reducers → store). It’s very structured but can be verbose. Ideal for larger applications that need predictable state transitions.
Zustand: A lightweight alternative to Redux. It uses simpler concepts (like hooks) and can be easier to set up for smaller or medium-sized applications.
Context + Custom Hooks: We might rely on React Context to provide global state, combined with custom hooks for reading and updating that state. This can be sufficient for smaller-scale apps.
Other Solutions (MobX, Recoil, etc.): There are many libraries in the React ecosystem for state management. The choice often comes down to team preference and project requirements.
Why Redux or Zustand?
Redux is known for its strict structure (actions, reducers, store) and is easier to debug using tools like the Redux DevTools.
Zustand is simpler to get started with and has less boilerplate. For a big feature set like Google Docs, we might lean towards Redux because of its debugging capabilities, but Zustand is a valid choice if the team prefers a minimalistic approach.
3.5 Handling Application-Wide State for Collaboration
Real-time collaboration isn’t just about storing the document’s text—it’s also about tracking each user’s cursor position, selection range, and presence (online/offline). We may also have to manage chat messages, comments, or user permissions.
To handle this, we’ll likely have a store (e.g., Redux store) that keeps track of:
Document Content State: The actual text (and its formatting).
Collaboration State: A list of active users, their cursor positions, and any ongoing edits that haven’t been synced yet.
UI State: Things like whether the sidebar is open, or which text formatting options are selected.
This store would be updated by actions like:
USER_JOINED_DOCUMENT: A new user opens the document.
USER_MOVED_CURSOR: A user changes their cursor position.
CONTENT_UPDATED: A user types or formats text.
Every time these actions occur, they cause an update in the store, which in turn re-renders the UI with the new data.
3.6 Separation of Concerns: UI, State Management, API Communication
A clean separation of concerns helps keep the codebase understandable:
UI Components: Focus solely on displaying data and triggering events (e.g., a button that calls “boldText()”).
State Management: Receives events, updates the store, and notifies components to re-render.
API/Network Layer: Defines functions or services that communicate with the backend. For example, saveDocumentChanges(changes) or fetchDocument(docId).
This approach makes it easier to test each part independently. For instance, we can write tests for our state management logic without worrying about the UI code. We can also swap out API endpoints (for example, moving from REST to WebSockets) without rewriting our entire application.
3.7 Efficient Data Structures for Text Editing
Text editors need fast insertion, deletion, and formatting. If we use a naive data structure (like a plain string), constantly adding or removing characters in the middle could become slow. Common approaches include:
Piece Tables: Store text in “pieces” rather than one long string, making insertions and deletions more efficient.
Ropes: A binary tree structure specialized for string operations.
CRDT-based Structures (for Real-Time Collaboration): If using CRDTs, the data structure might be more complex, designed so that changes from multiple users merge automatically.
If we’re using a rich text editor library (like ProseMirror or Draft.js), these libraries often abstract away the complexity of the internal data structure. They provide an API for applying operations (insert text, remove text, change formatting) while keeping performance optimal.
3.8 Storing Document Changes Before Syncing
In a collaborative environment, we don’t always want to send every single keystroke to the server the instant it happens. Instead, it’s common to:
Collect Edits Locally: As the user types, changes accumulate in a local buffer or queue.
Batch Updates: The system sends these changes to the server either periodically (like every few seconds) or after a certain number of changes. This helps reduce network overhead.
Handle Conflict Resolution or Transformations: When multiple users are editing at the same time, we need to transform the changes so they don’t override each other. This is where techniques like Operational Transformations (OT) or CRDTs come in.
By storing changes locally before syncing, we also improve the user experience during slow network conditions. The user sees their changes instantly (because it’s all local), and if the network is temporarily unavailable, the changes can sync once the connection is restored.
4. Real-Time Collaboration & Synchronization
Real-time collaboration is the heart of an application like Google Docs. It allows multiple users to work on the same document at the same time, see each other’s changes instantly, and keep the document in a consistent state. Below, we’ll explore how to implement real-time editing, handle conflicts, ensure low-latency updates, choose the right algorithm (OT vs. CRDT), manage efficient syncing, address disconnections/offline mode, and recover unsaved changes.
4.1 Implementing Real-Time Editing
To implement real-time editing, the frontend needs a mechanism to capture user input (like keystrokes, formatting changes, or cursor movements) and then instantly share these changes with other active collaborators. This typically involves:
Listening to User Events: Whenever a user types text, deletes content, or applies a style (like bold), the editor needs to capture that event. Most modern rich-text editors (Draft.js, Quill.js, ProseMirror, etc.) provide hooks or callbacks for these actions. For instance, if a user presses the “A” key, the editor can trigger a function that records “insert character ‘A’ at position X.”
Broadcasting Changes: Once the editor captures the change, it sends this information to a shared communication layer—often a server over WebSockets. WebSockets offer a persistent connection, meaning the server and all connected clients can instantly broadcast and receive updates.
Applying Changes Locally: Each collaborator’s editor also receives these updates. When user A adds a word, user B’s editor needs to insert that word at the exact same position to maintain a consistent view. This is done by applying the incoming change to the local document model.
Visual Feedback: Changes made by other collaborators might appear with coloured highlights, distinct cursors, or name labels. This gives each user a clear view of where others are editing in real time.
Implementing real-time editing thus involves tight integration between an editor component, a state management system, and a synchronization mechanism (like WebSockets or another real-time protocol).
4.2 Conflict Resolution Strategies
Conflicts occur when two or more users try to change the same part of the document at the same time. For example, if both user A and user B insert different text at the same position, the system needs a way to reconcile these edits without losing anyone’s contribution.
Last-Write-Wins (LWW): In the simplest approach, whichever user sends their change last will overwrite the other. However, this can be frustrating for users because it might erase someone’s edits. This approach is generally not user-friendly for text editors.
Operational Transformation (OT): OT transforms incoming edits so that they apply correctly, even if the document changed between the time of the edit and the time it was received. Essentially, if two users insert text at the same position, the algorithm offsets one user’s insertion so both get included. This ensures both edits survive, preserving intent.
Conflict-Free Replicated Data Types (CRDTs): CRDTs are data structures designed to resolve conflicts automatically without a central server deciding the outcome. Each user’s changes eventually converge to the same final state across all clients. CRDTs can handle complex text operations, but might require more memory and careful implementation details.
In practice, real-time text editors most commonly use OT or CRDTs because both allow for merges that keep everyone’s changes without overwriting. We’ll discuss the choice in more detail in Section 4.4.
4.3 Ensuring Low-Latency Updates
Low latency means that when a user types a character, all other users see that character appear almost instantly. To achieve this:
Use Persistent Connections: A WebSocket connection keeps an open communication channel, so the server can push changes immediately. Traditional HTTP polling can be too slow or inefficient, introducing noticeable delays.
Minimize Data Payloads: Instead of sending the entire document whenever something changes, we only send the “delta” (the small piece of changed data, like “insert ‘A’ at position 25”). This reduces network usage and speeds up updates.
Local Optimistic Updates: Show a change in the user’s own editor right away, without waiting for a server response. The application then confirms the change once it’s processed by the server. This approach makes the user’s experience feel instantaneous, though it requires careful handling if a server rejects or modifies the change.
Efficient Rendering: On the frontend, only re-render the portion of the text that changed, rather than re-rendering the entire document. Libraries like React let’s us control which components update to ensure the UI stays responsive.
4.4 Choosing Between Operational Transformation (OT) & CRDTs
Both OT and CRDTs aim to solve the same core problem: maintaining consistency across multiple users editing the same piece of text. However, they differ in their approach:
Operational Transformation (OT):
How it Works: When a new operation arrives (such as “insert character at position X”), the system checks how many operations have been applied to the document since that edit was created. It then “transforms” the new operation so that it applies cleanly on the updated text.
Pros: Well-tested in projects like Google Docs. It’s conceptually intuitive for text editing.
Cons: Requires a central server to serialize operations or a complex peer-to-peer approach. The transformation logic can become complex for advanced features like tables or embedded elements.
Conflict-Free Replicated Data Types (CRDTs):
How it Works: Each user’s edits are stored in a data structure that can merge automatically when states conflict. Every inserted character can have a unique identifier, allowing the structure to converge on a single order.
Pros: Peer-to-peer friendly, can work offline easily, and once we understand the concept, merges can be automatic.
Cons: Might use more memory because each character can carry additional metadata. The implementation can be tricky and less intuitive at first.
Choosing one often comes down to the team’s familiarity with these approaches, the complexity of the product, and performance constraints. Google Docs historically used OT, but many modern editors are experimenting with CRDTs due to their flexibility in offline/peer-to-peer scenarios.
4.5 Efficient Change Syncing with the Backend
Even though the frontend handles much of the collaborative logic, changes still need to be persisted to a server or cloud. The key considerations are:
Batch Updates: Instead of sending every single keystroke to the server individually, we can group updates together over short intervals (e.g., every 100-200 milliseconds). This avoids flooding the server with tiny requests.
Delta-Based Syncing: Only send the “differences” rather than the whole document. This keeps network usage low.
Document Versioning: Each time the document changes, increment a version number. That way, if the server receives updates out of order, it can still apply them in the correct sequence or request a re-sync if it detects a mismatch.
Conflict Handling: The server might also apply transformations (in the case of OT) or merges (in the case of CRDTs). The server’s role is to maintain an authoritative source of truth and distribute updated states back to all clients.
4.6 Handling Disconnections and Offline Mode
Real-time apps need a solid strategy for what happens when someone goes offline or their connection drops momentarily:
Automatic Reconnect: The frontend should detect when the WebSocket connection is lost and automatically attempt to reconnect at intervals.
Local Caching of Edits: If a user is offline, the editor can store changes locally (e.g., in IndexedDB or localStorage). When the connection is restored, it sends the stored changes to the server.
UI Indication: Show the user when they’re offline or reconnecting. Possibly disable collaborative features like seeing other people’s cursors in real-time, since those updates won’t be available offline.
Merge Upon Reconnection: Once the user is back online, the system merges their offline edits with the latest document version. With OT or CRDTs, this can happen seamlessly, but it’s crucial to ensure no data is lost if there were significant changes while they were disconnected.
4.7 Recovering Unsaved Changes
Users might accidentally close their browser, lose power, or refresh the page without explicitly saving:
Periodic Autosave: The frontend can autosave every few seconds, or whenever the user stops typing for a brief moment. These autosave triggers ensure the server always has a recent state of the document.
Local Backup: Even if the connection to the server fails, keep a local backup in IndexedDB or localStorage. Upon reopening, if the system detects unsaved local changes that weren’t synced to the server, it can prompt the user to restore them.
Version History: Maintain a lightweight version history so users can roll back to a prior state if something goes wrong. This can be as simple as storing deltas or more elaborate with a dedicated versioning server.
Graceful UI Prompts: If a user tries to close the tab while unsaved changes are pending, we can show a warning message or attempt to do a quick save. Modern browsers allow this with onbeforeunload events, although some have limitations on how much we can customise these prompts.
5. Performance Optimization
Building a real-time collaborative editor like Google Docs requires careful attention to performance because the application often deals with large documents, frequent user interactions, and live updates from multiple collaborators. Below are strategies and explanations to ensure the frontend stays responsive and smooth.
5.1 Ensuring Frontend Performance for Large Documents
When users work with large documents (hundreds of pages or thousands of paragraphs), performance can degrade if the browser tries to handle everything at once. Here are some simple strategies to keep things running efficiently:
Segment the document: Instead of putting all the text in a single large container, break the document into sections (like pages or chapters). This way, the browser only processes a part of the content at a time.
Load data progressively: When a user opens a large document, consider loading only the first few sections that are immediately visible. Additional parts of the document can be fetched or rendered only when needed.
Use efficient data structures: Storing text in arrays or specialized data structures (like piece tables or rope data structures) helps ensure that insertions and deletions are handled quickly. This can prevent delays when users type or delete text.
Goal: The main goal is to avoid loading everything upfront and to minimize the workload on the browser so the editor remains fast and responsive.
5.2 Optimizing Rendering of Text Documents
Rendering is the process by which the browser takes the HTML (and associated JavaScript and CSS) and displays it on the screen. For a text-heavy application like Google Docs, rendering optimization is crucial:
Minimize DOM Nodes: Every piece of text in a document corresponds to a DOM (Document Object Model) node. If we have thousands of paragraphs each wrapped in multiple HTML tags, we could have a very large DOM tree. A large DOM slows down the browser.
Tip: Merge adjacent text nodes or reduce extra HTML tags to keep the DOM as small as possible.
Batch Updates: Instead of updating the DOM on every single keystroke, batch multiple changes together. Modern libraries like React do this batching automatically, but it’s important not to do extra renders in our own code.
Avoid Re-renders: Use libraries or built-in features (like React’s memo or PureComponent) to re-render only the pieces of the UI that have actually changed.
Goal: Ensure that when the user types or scrolls, the application updates quickly without re-rendering large portions of the screen unnecessarily.
5.3 Virtualization Strategies (e.g., react-window)
Virtualization means that instead of rendering all the content in the DOM at once, we only render what is visible plus a small buffer above and below the visible area. For example, if the user sees only 20 lines of text on the screen, we only keep 20–40 lines in the DOM, not the entire document.
react-window or react-virtualized are popular libraries that handle this automatically. They calculate which elements should be shown based on the user’s scroll position and dynamically remove off-screen elements from the DOM.
Benefits:
Reduced DOM size: The browser only deals with a small number of elements at any given time.
Faster rendering: Less content to layout and paint.
Efficient memory usage: We don’t keep thousands of paragraphs in memory if they are not currently needed.
This approach is extremely helpful if a user is working on a document with hundreds or thousands of pages because it ensures that only the visible portion is actively managed by the browser.
5.4 Efficient Undo/Redo Implementation
An editor must offer undo and redo so users can revert changes or restore them. However, storing the entire document each time can quickly blow up memory usage and slow down performance. Here’s how to handle this more efficiently:
Store Differences (Deltas): Instead of saving the entire document state, save only the differences (or “diffs”) between consecutive states. For example, if a user types the letter “A,” we store just “+A at position 100,” not the entire document text.
Use a Stack: Commonly, we keep two stacks—one for undo operations and another for redo. When the user undoes an action, we pop from the undo stack and apply it in reverse, then push it onto the redo stack.
Limit History: For performance, we might limit the history to a certain number of actions (e.g., 100). This prevents the application from storing an excessive number of changes.
This strategy ensures fast undo/redo operations without burdening the system with huge snapshots of the document at each step.
5.5 Optimizing Cursor Movement and Selection Tracking
In a live document editor, the position of the cursor and selected text must update in real-time. When multiple users are editing, each user’s cursor or selection can appear on screen. Here’s how to keep it efficient:
Use Lightweight Representations: Store a cursor position as a simple integer that marks where in the text the cursor is. For selections, store a start and end index (like [startIndex, endIndex]).
Only Update When Needed: If the cursor is stationary and the user isn’t typing, there’s no need to constantly recalculate its position. Updates only matter when the user presses keys or moves the mouse.
Batch Collaborator Updates: When receiving updates about other users’ cursors, group these updates and apply them together, instead of adjusting them one by one in rapid succession.
This approach ensures that the editor remains snappy and that the cursor and selection are accurate without draining resources.
5.6 Avoiding Unnecessary Re-Renders in React
React apps can re-render multiple times if we’re not careful. Every re-render can lead to new calculations, new layouts, and potentially slow down the app. Some tips to avoid over-rendering:
Use Memoization: React’s memo (for function components) or PureComponent (for class components) helps skip re-renders when props haven’t changed.
Optimize Redux or Other State Libraries: If we use something like Redux or Zustand, ensure that state updates are as minimal as possible. For instance, store only necessary slices of data at each component level.
Split Components: Break down large components into smaller ones. The smaller component only re-renders when its local props or state change.
Avoid Inline Functions or Objects: In React, inline objects and functions can cause frequent re-renders because references change on every render. Instead, define functions outside the render method or use useCallback.
By carefully managing how components receive and use data, we can significantly cut down on wasted re-renders.
5.7 Lazy Loading for Large Documents
Lazy loading means loading parts of our application (or data) only when needed. For a document editor:
Chunk the Document: Perhaps load the first few pages of a document right away, and then fetch more pages only when the user scrolls to the bottom of the visible content.
Deferred Rendering: We can also defer non-critical UI elements (like user avatars or certain toolbar features) until after the main editor is ready. This technique ensures the core editing experience loads faster.
Lazy loading is similar to virtualization in concept but focuses more on when data is fetched rather than how it’s displayed. Together, they help ensure the user never has to wait long to start editing or viewing the document.
5.8 Debouncing and Throttling Updates
Debouncing and throttling are techniques to control how frequently certain events trigger code execution. In a text editor, users might type very quickly, generating many events in a short time. Sending every keystroke to the server could cause network overload and slow down the client.
Debouncing: Wait until the user stops typing for a short interval (e.g., 300ms) before sending updates or doing heavy computations. This way, if the user types quickly, the function only runs once after they pause.
Throttling: Execute the update function at a set maximum rate. For instance, we might only allow one server update per second, even if the user types 10 characters in that second.
By debouncing or throttling updates, we reduce unnecessary operations and keep the editor feeling responsive. It also prevents flooding the server with too many requests at once.
6. Caching & Data Persistence
Caching and data persistence are crucial for a web-based editor like Google Docs. They help ensure that users don't lose their work, even if their internet connection fails, and they also make the app faster by avoiding unnecessary network calls. Below, we’ll discuss various strategies and tools to achieve efficient caching and data persistence in a user-friendly document editor.
6.1 Using LocalStorage, IndexedDB, or Service Workers
LocalStorage
What It Is: LocalStorage is a simple key-value storage mechanism provided by the browser. Each value is stored as a string.
When to Use: It’s best for small amounts of data, like user preferences or simple flags (e.g., “night mode” on/off).
Pros: Very easy to use, synchronous access, widely supported in modern browsers.
Cons: Limited storage space (usually around 5–10 MB), and because it’s synchronous, it can block the main thread if we store too much data.
IndexedDB
What It Is: IndexedDB is a more robust database system in the browser. It allows us to store large amounts of structured data.
When to Use: It’s perfect for storing offline data for documents, like partial or full versions of a file, because we can store complex objects and larger amounts of data than LocalStorage can handle.
Pros: Asynchronous, can handle more data, supports indexing for faster queries.
Cons: Slightly more complex API compared to LocalStorage.
Service Workers
What They Are: Service Workers run in the background, independent of our web page. They can intercept network requests and manage a cache of responses (using the Cache API).
When to Use: Ideal for offline capabilities. When the user goes offline, Service Workers can serve cached files or data so the app still works to some extent.
Pros: Excellent for building Progressive Web Apps (PWAs). Can handle offline requests and push notifications.
Cons: More complex to set up and maintain, requires a careful design to handle multiple caches and updates.
Overall, choosing the right storage mechanism often involves using a combination of these tools. For example, we might cache static assets (like images or JavaScript bundles) using Service Workers, keep important user data (like partial document edits) in IndexedDB for offline access, and store quick flags or states (like user settings) in LocalStorage.
6.2 Implementing Efficient Autosave Functionality
Autosave is the process where changes in a document are saved automatically without requiring the user to press a “Save” button. This feature is critical for avoiding data loss and improving user experience.
Capturing Changes
In a document editor, every keypress or formatting change can generate an “edit event.” Instead of sending every single event to the server in real-time, we can accumulate these edits in a small buffer in the frontend.
This buffer will temporarily store changes (e.g., typed characters, deletions, formatting commands, etc.).
Saving at Intervals or Triggers
Timed Interval: We can save changes every few seconds (e.g., every 5 seconds). If the user is actively typing, the system automatically collects edits and commits them to the backend after this interval.
Idle Detection: Another approach is to save when the user stops typing or becomes idle. This can reduce the load on the server because we’re not sending updates while the user is actively typing.
Combination: Most modern solutions use both a short timed interval and an idle check for optimal performance and reliability.
Local Caching Before Server Sync
To handle sudden disconnections, we can store the latest edits in IndexedDB or LocalStorage (if small) every time we perform an autosave action.
Once the connection is re-established, these cached edits are synced with the backend, ensuring minimal data loss.
By blending interval-based saving with local caching, we can create a robust autosave mechanism that protects users from accidentally losing their work.
6.3 Caching Strategy for Reducing API Calls
For a tool like Google Docs, the user might open and edit multiple documents frequently. Repeatedly fetching the same data from the server can increase loading times and waste bandwidth.
Document Metadata Caching
Instead of fetching a complete list of documents every time, we can store document metadata (like titles, last-modified times, owner info) in a local cache (IndexedDB or LocalStorage).
When the user opens the app, we check our local cache first. If the cached data is recent, we avoid extra server calls.
Partial Document Caching
For large documents, we might cache the most recently accessed portions, such as the first few pages or the most recent edits, in local storage.
This way, the editor can load instantly while additional data is fetched in the background.
Intelligent Invalidation
A good caching strategy includes a way to invalidate or update cache entries when they become stale.
For instance, if a document was edited on another device, we should detect that (e.g., through a version identifier) and refresh the local cache to stay consistent.
By carefully deciding what data to cache and when to invalidate it, we can significantly reduce the number of redundant API calls and make the application more responsive.
6.4 Document Preloading for Faster Access
Document preloading is a technique where the application anticipates the user’s next actions and starts fetching data proactively.
Predictive Loading
If a user is browsing a list of documents, the system might pre-fetch the first page or summary of the next likely document they will open (based on recent activity or user behaviour).
For instance, if the user is currently in a folder with several documents, we might preload metadata or partial data for those documents in the background.
Immediate Availability
By the time the user clicks on a document, most (or all) of its data is already in local storage or the cache, allowing the editor to open it almost instantly.
Balancing Bandwidth and Performance
Preloading should be done carefully to avoid using too much bandwidth, especially on mobile networks.
A common approach is to preload only small chunks of data (metadata, partial contents) and load the rest only if the user actually opens the document.
Preloading is a balancing act: it can dramatically speed up the user experience but must be controlled to prevent unnecessary data usage.
6.5 Handling Document Versioning
Versioning ensures that users can revert to previous states of a document and that multiple versions (or forks) of a document can be maintained without confusion.
Why Versioning Matters
It allows users to see the document’s history (revision history).
In real-time collaboration, multiple users may be making changes simultaneously. Versioning provides a systematic way to track these changes.
Version Identification
Each significant state of the document can be assigned a version identifier (e.g., a timestamp or a unique version number).
When new edits come in, the system creates a new version while still retaining the old one.
Delta Storage vs. Full Snapshots
Full Snapshots: Store the entire document as a separate copy for each version. This is simpler but consumes more space.
Delta Storage: Store only the differences (edits) between versions. This saves space but is more complex to implement.
Many modern solutions use a hybrid approach where we occasionally store a full snapshot (e.g., once an hour or once a day) and store deltas in between. This prevents needing to recalculate too many deltas if we want to revert to an older version.
Frontend and Backend Collaboration
While the backend is primarily responsible for maintaining official versions, the frontend should be aware of the current version (or revision) it’s editing.
When the user saves or autosaves, the frontend sends its version identifier along with the changes. This helps the backend detect if the user is editing an outdated version and merge changes appropriately.
By designing a clear versioning system, we give users the freedom to explore different revisions of a document safely and also provide an essential foundation for real-time collaboration and conflict resolution.
7. Security & Access Control
Building a secure environment in a real-time collaborative system like Google Docs is crucial to protect users’ data and maintain trust. In this section, we will explore how to secure user data, prevent common vulnerabilities, manage permissions, and maintain robust authentication.
7.1 Securing User Data in the Frontend
Securing user data on the frontend involves ensuring that sensitive information is never exposed to unauthorized parties. While most security measures happen on the backend (e.g., storing data in secure databases), the frontend still has vital responsibilities:
Using HTTPS (TLS/SSL):
Always communicate over a secure HTTPS connection. This encrypts the data traveling between the user’s browser and the server, preventing eavesdropping or data tampering.Avoid Storing Sensitive Data in Plain Text:
If we need to store temporary user information (like tokens) in the browser, consider secure storage mechanisms:HTTP-Only Cookies: Tokens stored in HTTP-only cookies cannot be accessed by JavaScript, reducing the risk of certain attacks.
Local Storage or Session Storage: If we must use local or session storage, ensure we don’t store highly sensitive data for long. We should also protect against Cross-Site Scripting (XSS) that might try to steal this data.
Protecting Against Content Leaks:
Make sure our application doesn’t inadvertently leak data in places like:URL Query Parameters
Browser console logs
Error messages or stack traces
By keeping data encrypted in transit, avoiding plain-text storage, and minimizing leaks, we significantly reduce the risk of compromised user data on the frontend.
7.2 Preventing XSS and CSRF Attacks in a Real-Time Editor
Cross-Site Scripting (XSS) and Cross-Site Request Forgery (CSRF) are common security threats for web applications, especially those that handle user-generated content in real time.
Cross-Site Scripting (XSS)
What is XSS?
XSS occurs when an attacker injects malicious scripts (JavaScript) into a web page that other users view. If our editor doesn’t sanitize or validate user input, an attacker could insert harmful scripts into the document.How to Prevent It
Input Sanitization: Whenever a user enters text (or any data), make sure we remove or encode any suspicious code. Many rich text editors (like ProseMirror, Draft.js, or Quill) have some built-in sanitization, but we should still validate all content before it’s rendered.
Escape User-Generated Content: When displaying content in the browser, escape HTML tags so that they render as text rather than executable code.
Content Security Policy (CSP): Configure a strict CSP in our application settings. This can prevent inline scripts from running and restrict the sources from which scripts can load.
Cross-Site Request Forgery (CSRF)
What is CSRF?
CSRF occurs when a malicious website tricks a user into performing actions on another site where they are already authenticated. For example, if we’re logged into Google Docs, and we visit a harmful website, that website might try to make requests on our behalf to Google Docs.How to Prevent It
CSRF Tokens: The server generates a random token and includes it in each HTML form or request. The application verifies the token on every write/update request. If the token is missing or invalid, the request is rejected.
SameSite Cookies: Setting cookies as SameSite=strict or SameSite=lax helps prevent them from being sent with cross-site requests, reducing CSRF risk.
By combining robust input validation, output escaping, token-based verification, and a solid Content Security Policy, we can greatly reduce the risk of XSS and CSRF in our real-time editor.
7.3 Role-Based Access Control (RBAC) for Editing, Commenting, and Viewing
Role-Based Access Control ensures different users only have the permissions that match their roles. For a document editor like Google Docs, common roles might include:
Owner: Full control over the document, including setting permissions for others.
Editor: Can modify the document content.
Commenter (or Reviewer): Can view and add comments but cannot edit.
Viewer (Read-Only): Can only read the document.
Implementation Approach:
User and Permission Mapping:
Each user is mapped to a role for a specific document. For instance, a user’s role might be “Editor” for Document A but only a “Viewer” for Document B.Frontend Enforcement:
The application checks the user’s role and shows/hides UI elements based on their permissions (e.g., show the “Edit” button only to Editors or Owners).API-Level Enforcement:
Even if the user manipulates the UI in the browser, requests to edit or delete content should be verified on the server to ensure the user truly has the right role. This prevents malicious attempts to bypass the frontend.
RBAC helps maintain an organized permission structure so that only authorized individuals can modify or view certain data.
7.4 Ensuring End-to-End Encryption for Documents
End-to-end encryption (E2EE) means the document is encrypted on the user’s device and remains encrypted in transit and at rest, so not even the server can read it unless specifically allowed.
How It Works:
Key Generation: Each document could have its own encryption key. When a user creates a document, the system generates a unique key locally in the browser.
Encryption Before Upload: Before any content is sent to the server, the editor uses this key to encrypt the text. The server only stores or transmits encrypted data.
Decryption on Download: When a collaborator opens the document, the key must be securely shared (often through separate channels or using the server with additional security) so that the content can be decrypted in their browser.
Challenges with E2EE:
Key Management: Ensuring only authorized users get access to the decryption key can be complex.
Search and Indexing: If the content is fully encrypted, the server can’t index it or perform full-text searches easily unless additional mechanisms are used.
Despite the complexity, E2EE is a strong measure for protecting sensitive documents against unauthorized access—even if the server is compromised.
7.5 Authentication and Authorization (OAuth, JWT)
To control who can access a document (and what actions they can perform), we need robust authentication and authorization.
Authentication: Confirming the user’s identity.
Authorization: Verifying that the user has permission to perform an action.
Common Methods:
OAuth 2.0:
Typically used when we’re integrating with external identity providers such as Google, Facebook, or Microsoft.
The user logs in using the external provider, and our app receives an access token that proves the user’s identity.
JSON Web Tokens (JWT):
A self-contained token that includes user information, expiration time, and signature.
The token can be stored in a secure HTTP-only cookie or local storage.
The server verifies the signature on each request to ensure the token is valid.
Implementation Flow:
The user logs in through OAuth or our custom login form.
The server issues a JWT or session ID.
The frontend stores this token safely (ideally in an HTTP-only cookie).
For each subsequent request (e.g., saving a document), the token is sent to prove the user’s identity.
The server checks the token, determines the user’s roles/permissions, and either grants or denies access.
By combining proper authentication with RBAC, we ensure that only legitimate, correctly permissioned users can access or modify documents.
7.6 Preventing Malicious Script Injections in a Rich Text Editor
Real-time document editors often allow users to embed rich text, images, and potentially other media. This freedom can be dangerous if not handled carefully, because malicious users can try to inject harmful scripts or iframes.
Sanitizing User Input:
Use libraries that sanitize and clean up HTML content before it is rendered. For example, any tags like <script> should be removed, and attributes like onerror or onload in images should be stripped.Limiting Allowed HTML Elements:
We can maintain a whitelist of safe HTML tags (<b>, <i>, <u>, <p>, etc.) and disallow everything else. Similarly, we can restrict certain attributes (like style or href) to ensure no hidden scripts are embedded.Using Iframes Safely:
If we allow iframes, make sure they are sandboxed (using the sandbox attribute) so they can’t execute arbitrary JavaScript or interact with the parent page.Real-Time Checks:
In a live collaboration scenario, each user’s changes should be validated or sanitized on the client before sending them out to other collaborators. The server can then double-check this sanitization as well.
8. Collaboration Features
Collaboration features are what make Google Docs more than just a text editor. These features enable multiple people to communicate, share ideas, suggest changes, and track progress—all in real-time. Below, we’ll dive into each major collaborative feature in detail.
8.1 Implementing Commenting and Annotation
What is it?
Commenting and annotation let users highlight parts of the document and leave notes or feedback for others. For instance, we might select a sentence and comment, “Can we simplify this phrase?” or “Need a source here.” Annotations often appear as highlights in the text, with a small panel or popup displaying the feedback.
Key Considerations:
Selecting Text Ranges:
When a user highlights text and clicks “Add Comment,” the system needs to record the exact start and end points of that highlight in the document. This is often done by tracking the character indices or storing a unique identifier for each segment of text.
Frontend Data Structure:
We might store comments in a dedicated data structure that associates a text range with the comment content. For example:
{
"commentId": "unique-id",
"range": { "start": 250, "end": 272 },
"text": "This is the highlighted part",
"author": "User123",
"message": "Need to clarify the meaning",
"timestamp": 1678892200
}These objects can be kept in the application state (e.g., in Redux or a local state management library).
Displaying Comments:
The editor UI can visually mark the highlighted section. When the user hovers or clicks on that highlight, a small popup or side panel can appear showing the comment details.
A separate side panel can list all comments in chronological order or grouped by paragraph.
Real-Time Updates and Resolving Comments:
As soon as a comment is created or updated, those changes should be sent to other users in real-time so they can see the feedback immediately.
If a comment is resolved (marked as complete), it should be hidden or shown as “resolved” for everyone else.
How it Works in Practice:
User A highlights text in the document and clicks “Add Comment.”
A small form appears to type in feedback.
Upon saving, the highlighted text changes color, and the new comment is stored in a shared state that’s synced with the server (e.g., via WebSockets).
User B sees the comment appear in near real-time. They can reply or resolve it.
Any resolution or reply is also synced so that User A sees it immediately.
8.2 Designing an In-Document Chat System
What is it?
An in-document chat is a live chat feature embedded in the editor interface. It allows collaborators to discuss ideas or issues without leaving the document or using a separate tool.
Key Considerations:
Chat UI Placement:
Often, the chat appears in a collapsible sidebar or a small popup window so it does not obstruct the document. The placement should be intuitive (e.g., a “Chat” icon in the top-right corner).
Real-Time Messaging:
Messages should appear instantly (or as close to instantly as possible) for all participants. This is typically done using a real-time protocol like WebSockets.
Each message can contain sender info (avatar, name), timestamp, and the message text.
Backend and Storage:
Messages could be temporarily stored in the frontend state. At the same time, they are sent to the server and broadcasted to other users’ clients.
A simple data structure might look like:
{
"messageId": "unique-id",
"author": "User123",
"content": "Hello everyone!",
"timestamp": 1678892400
}The server can store the chat history so that new users joining the document can see previous messages.
Notifications and Presence:
If a new message arrives while someone is not looking at the chat, a small notification can appear.
“Presence indicators” can show which collaborators are online and viewing the document.
How it Works in Practice:
User A opens the chat panel and types a message: “Let’s move section 2 to the top.”
The frontend sends this message via WebSockets to the server.
The server immediately relays the message to all connected clients.
User B sees the message appear in the chat panel. They can respond without leaving the document.
8.3 Displaying Cursors and Selection Highlights for Multiple Users
What is it?
When multiple users work on the same document, it’s helpful to see exactly where each person’s cursor is, as well as any text they have highlighted. This feature makes collaboration more transparent and reduces confusion about who is editing what.
Key Considerations:
Tracking Cursor Position:
Each user’s cursor can be identified by a unique color or name tag.
The application needs to communicate cursor position changes to the server (e.g., every time the user moves their cursor with arrow keys or a mouse click).
Updating Other Clients:
When the server receives a cursor update, it broadcasts the new position to other connected clients.
Those clients then render a small cursor icon (often with the user’s name or avatar).
Highlighting Selections:
If a user selects a range of text (e.g., from character 100 to 120), that range can be highlighted in a semi-transparent color unique to the user.
Similar to cursor position, these selections need to be shared in real-time.
Performance Considerations:
Cursor movements can change many times per second. To avoid overloading the network, we might throttle or debounce updates so they only happen when necessary (e.g., after a slight pause).
How it Works in Practice:
User A clicks on line 10, moving their cursor to that position.
The editor captures the new cursor position and sends it to the server.
The server relays the position to other users.
User B’s browser receives this update and draws a small cursor icon at the specified location, labeled “User A.”
If User A selects text, the highlight range is communicated in a similar manner.
8.4 Implementing Track Changes (Suggestion Mode)
What is it?
Track Changes, often called “Suggestion Mode,” is a feature that logs every edit (insert, delete, format change) as a suggestion, rather than committing it immediately. Collaborators can then review each change, accept or reject it, and leave comments on individual suggestions.
Key Considerations:
Capturing Edits:
Each keystroke or formatting change can be recorded along with metadata, like which user made the change, when it was made, and the original vs. updated text.
The system might need to store these edits as separate “diff” objects, such as:
{
"changeId": "unique-id",
"author": "User123",
"timestamp": 1678892600,
"oldText": "Hello",
"newText": "Hi",
"range": { "start": 50, "end": 55 }
}Visual Representation:
Inserted text might appear in a different color or underlined to show it’s a suggestion.
Deleted text might appear with strikethrough, often in red, to indicate it’s proposed for removal.
Accepting or Rejecting Changes:
Users can hover over a suggested change to see who proposed it and click “Accept” or “Reject.”
When accepted, the suggestion becomes part of the final text. When rejected, the text reverts to the original.
Synchronization:
As soon as a change is made, it should appear in real-time for other collaborators.
Accept/Reject actions should also sync so that everyone sees the updated document.
How it Works in Practice:
User A toggles “Suggestion Mode” on and types “Hello” into the document.
The system records an “insert” suggestion from User A. The new text appears highlighted or underlined.
User B sees the suggestion appear in their view. They can click on it, see it’s from User A, and choose to accept or reject.
If User B clicks “Accept,” the text becomes regular (non-highlighted), and the old version disappears.
8.5 Implementing @Mentions and Notifications
What is it?
@Mentions allow us to tag a specific person in a comment or in the document text, which usually triggers a notification to that person. This makes it easy to get someone’s attention or ask for input.
Key Considerations:
Detecting the “@” Character:
While typing a comment or in a chat box, when a user types “@,” the system can open a dropdown menu of possible people to mention.
This requires fetching a list of collaborators or user contacts, often via an API.
Linking to a User Profile:
Once a mention is selected (e.g., “@User B”), the system stores metadata linking that mention to a user ID.
The mention text might show up as clickable to reveal the user’s info or send them a direct notification.
Notifications:
Typically, a notification system will either email the tagged user, send them a push notification, or highlight the mention in the UI.
On the frontend, we might maintain a small notification center or badge indicating unread mentions.
Real-Time Updates:
If user B is online at the same time and is tagged in a comment, they can see it instantly pop up, possibly with a beep or visual alert.
How it Works in Practice:
User A types a comment: “@User B, can we clarify this section?”
The system recognises the “@” symbol, shows a dropdown, and User A picks User B’s name.
The mention data is saved in the comment object, and a real-time message is sent to User B’s client.
User B sees a notification appear in the document or receives an email/push notification, depending on their preference.
8.6 Efficient Edit History & Revision Tracking
What is it?
Edit history (or revision history) allows users to view past versions of the document. They can see who made changes, when those changes were made, and what was changed. Some systems allow restoring the document to an earlier version.
Key Considerations:
Versioning Strategy:
A common method is to store “snapshots” of the document at significant points (like every few minutes or when the user manually requests).
Alternatively, we can store every change (or “delta”) so we can reconstruct any version by applying these deltas in sequence.
Retrieving Past Versions:
When a user requests a previous version, the system either:
Loads a past snapshot directly, or
Replays the changes from the original version up to that point in time.
For large documents, storing every single version as a full snapshot can be expensive. Hence, a delta-based approach is often more space-efficient.
UI for Revision History:
Typically, a “History” panel can show a timeline of edits. Clicking a specific timestamp or version ID reveals how the document looked at that moment.
Users can compare two different versions or restore an older version entirely.
Real-Time Collaboration Impact:
Because multiple people can edit at once, the revision history has to capture merges of all those edits correctly. This is why robust real-time synchronisation methods (e.g., OT or CRDT) are crucial; they keep a consistent record of all changes.
How it Works in Practice:
User A and User B edit the document simultaneously, generating a sequence of changes or version checkpoints.
The system stores these changes on the server with timestamps and user IDs.
When User A opens the revision history view, they see a chronological list of changes.
Clicking on a past revision loads that version’s content into a read-only mode, allowing User A to decide whether to revert or simply inspect it.
9. Offline Mode & Synchronization
9.1 Designing an Offline-First Editing Experience
An offline-first approach means we assume our users might go offline at any time, and we design the system to handle this gracefully. In practical terms:
Local Storage of Document Data
When a user opens a document, the editor immediately caches the document data on their device. A common choice for storing this data is IndexedDB in the browser. IndexedDB is preferred over localStorage for large text data because it can handle bigger chunks of data more efficiently.
This offline storage contains not just the initial document content but also any in-progress edits or changes the user makes.
Immediate Document Interaction
Once the editor has the document data locally, the user should be able to edit without waiting for a round-trip to the server. This makes the user experience fast and fluid, even if the network is slow or temporarily unavailable.
UI Feedback for Connectivity
The editor can display a simple status indicator—for example, a small icon or label that says “Online” or “Offline.” When the internet connection is lost, it can switch to “Offline” mode, reassuring the user that changes are still being saved locally and will be synced later.
Service Workers (Optional but Helpful)
Service Workers allow us to intercept network requests and serve cached assets (HTML, CSS, JS) or even data from IndexedDB. This ensures the editor loads instantly even when the user is offline.
They also enable background syncing once the connection is restored, meaning we don’t have to rely solely on the active browser tab to push changes.
9.2 Syncing Offline Changes with the Server
Once the user regains connectivity, the application must synchronize all offline edits with the server. The primary challenge is to merge changes made offline with any changes that might have occurred on the server in the meantime.
Local Queue of Changes
Each time the user makes an edit while offline, this edit is recorded in a local queue stored in IndexedDB or a similar offline storage mechanism.
Instead of storing the entire document repeatedly, it’s more efficient to store small patches or diffs that represent what changed in the document.
Check for Connectivity
When the browser detects that the internet is back (for example, through an event listener on window.ononline or by periodically pinging the server), the application attempts to send these queued changes to the server.
If the server responds that it’s receiving changes successfully, the local queue can start clearing out the edits that have been acknowledged by the server.
Pull Latest Server State
While offline, someone else might have edited the same document. So, after pushing our local changes, we also pull the latest version from the server.
This is where conflict resolution enters the picture. The server might say, “Hey, I’ve got a different version of the document than we do.” The application then merges those changes with the local version.
Visibility to the User
The editor can briefly show a “Syncing…” message or animation, so the user knows the system is connecting and sending updates.
Once syncing is complete, the status can switch to “All changes saved.”
9.3 Handling Conflicts Between Offline and Online Changes
Conflicts occur when multiple users edit the same portion of a document at the same time, or when we come back online and discover that the server has a different state than our local copy. Handling conflicts in a user-friendly way is crucial.
Operational Transformations (OT) or CRDTs
One way to handle conflicts is through Operational Transformation (OT), a technique where each edit is represented as an operation (e.g., “insert character X at position Y”). OT servers keep track of operations from each user, transform them so they remain compatible with other simultaneous edits, and produce a final consistent state.
Another option is Conflict-free Replicated Data Types (CRDTs), which can merge changes from multiple concurrent editors automatically without requiring a central server to transform operations.
User Notification vs. Automatic Merge
Some conflicts can be safely merged automatically (like two different users inserting text at different places in the document).
If two users edit exactly the same text, the system might have to show a merge conflict resolution UI. In practice, advanced editors (like Google Docs) rarely show a direct conflict interface; instead, they handle it in real time with more sophisticated algorithms.
Versioning and Revisions
It’s often helpful to maintain a history of versions. If the merge doesn’t turn out the way a user expects, they can revert to a previous state. The presence of revision history makes conflicts less scary because we can always undo or roll back undesired changes.
9.4 Delta-Based Synchronization Mechanism
A delta-based synchronization mechanism is crucial for both performance and reliability. Instead of sending the entire document on every change, deltas (or patches) contain only the minimal changes that occurred since the last known state.
What is a Delta?
A delta is a compact representation of changes, such as “User inserted the word ‘hello’ at index 50” or “User removed 5 characters at index 30.”
These deltas can be small JSON objects or specially formatted messages. The idea is to send as little data as possible over the network.
How Deltas Work in Real-Time
In real-time editing, every keystroke (or batched collection of keystrokes) generates a delta. For instance, typing “Hi!” could generate multiple deltas—one for H, one for i, one for !—but we can batch them into a single delta if we want fewer network calls.
When the server receives a delta, it applies it to the current document version on the server. Simultaneously, other connected clients receive the delta and apply it to their local copies.
Offline Scenario with Deltas
While offline, our deltas are stored locally in a queue. When we come back online, these deltas are sent to the server in sequence.
The server merges them with any deltas that arrived in the meantime from other users, ensuring a consistent final document.
Benefits of Delta-Based Approach
Efficiency: Sending just the changes is significantly lighter than sending the entire document. This makes real-time updates faster and reduces bandwidth usage.
Conflict Handling: Using OT or CRDT algorithms on top of deltas is more straightforward than trying to reconcile entire document states repeatedly.
Scalability: Delta-based synchronization scales better because the server deals with relatively small messages instead of massive text payloads.
10. Scalability & Multi-Tenancy
10.1 Scaling to Support Millions of Concurrent Users
Scaling our frontend system to handle millions of users at the same time involves multiple strategies that ensure both reliability and speed. At its core, we want to make sure that no single server or data center becomes a bottleneck for users trying to open and edit documents.
Distributed Infrastructure:
One way to handle high traffic is to distribute our servers and data storage across multiple regions. For instance, we can place servers in different geographical areas, such as North America, Europe, and Asia. This allows users to connect to the server closest to them, reducing latency (the delay before data starts to move).Content Delivery Networks (CDNs):
A CDN is like a network of proxy servers spread out around the world. When a user opens our Google Docs frontend, all the static files (HTML, CSS, JavaScript) can be delivered from a location near them. This decreases load time since data travels a shorter distance.Load Balancing:
Load balancers act like traffic cops, directing user requests to the least busy server. This ensures that no single server is overwhelmed by user requests while others sit idle. When we have load balancers in place, we can easily add more servers during peak times (horizontal scaling).Efficient Frontend Caching:
Using browser caches and service workers, we can temporarily store certain assets or even partial data on a user’s device. This strategy reduces the number of requests made to the server, which is crucial during high-traffic situations.Optimizing Code and Minimizing Payloads:
Every kilobyte matters when millions of people access the application concurrently. Techniques like code splitting, tree shaking, and minification can reduce the overall size of our JavaScript and CSS files, making pages load faster under heavy load.
10.2 Efficient Document Sharing Across Teams
In a large organization, multiple teams often need to work together on the same document or on a set of documents. Efficient sharing is essential to maintain productivity and prevent confusion over who has access to what.
Granular Access Controls:
We can provide different permission levels (e.g., Editor, Commenter, Viewer) to each user or group. This allows us to tailor the user’s access based on their role or project needs. For instance, a design team might have editing rights, while stakeholders only have viewing rights.Shared Workspaces:
A shared workspace acts like a virtual folder where team members can see all the documents relevant to them. This eliminates the need for everyone to keep separate copies. When changes are made in real time, all members see the updated version immediately.Search and Tagging:
As the number of documents grows, finding the right one can be challenging. Adding a powerful search feature that sorts by title, tags, or content is crucial. Tagging documents by project, department, or topic can also speed up the search process.Link-Based Sharing:
Often, we might want to generate a link that can be shared with others for quick collaboration, especially if they’re external to the organization. This link can have specific permissions attached to it, such as “view only” or “edit.”
10.3 Supporting Multi-Tenancy for Organizations and Individuals
Multi-tenancy means running a single instance of our application (the code and the infrastructure) to serve multiple “tenants” (which can be individual users or entire organizations) while keeping their data separate.
Tenant Isolation:
Each tenant should have its data logically (and sometimes physically) separated from other tenants. For example, large companies might want their documents stored in their own database schema, while smaller users could be grouped in a shared schema but with strict access controls to prevent any cross-tenant data leakage.Configurable Customization:
Different organizations often have different branding or feature preferences. Our frontend might allow tenants to apply custom themes or disable certain features based on their subscription level. By adding feature flags or configuration files, we can toggle features for different tenants without creating a separate codebase.Single Sign-On (SSO) and Role Management:
In a multi-tenant environment, we might have to integrate with various identity providers (like Google Workspace, Microsoft Active Directory, or custom OAuth servers). Supporting SSO makes it easier for organizations to manage who has access.Scalable Databases:
Under a multi-tenant model, we need a database strategy that can handle tenant isolation at scale. This might include having separate databases for premium tenants or sharding our database by organization to ensure performance doesn’t degrade with growth.
10.4 Performance Testing for Scalability
Performance testing is vital to confirm that our frontend can maintain quick response times as the user base increases. It also helps us identify bottlenecks before they become real user complaints.
Load Testing:
Load testing involves simulating a large number of users accessing the system at the same time. Specialized tools (like Apache JMeter or Locust) can send massive amounts of requests to our servers, mimicking real-world traffic. By monitoring how our application responds—what the average response time is, how many requests fail—we can gauge its breaking point.Stress Testing:
Stress testing pushes our system beyond normal capacity (extreme traffic) to see how it behaves under maximum load. This helps us discover the “worst-case scenarios.” We can check if the application fails gracefully (e.g., providing an error message) rather than just crashing.Latency and Throughput Metrics:
Metrics like “latency” (time to respond to each request) and “throughput” (how many requests can be handled in a given time) are essential. By measuring these, we can find where our system slows down and whether it needs more servers, more efficient code, or better databases.Monitoring and Logging:
We need to keep a close eye on how our application performs over time. Setting up real-time dashboards that show CPU usage, memory, and network traffic can help us quickly detect unusual spikes or dips. Logging user activity and errors can also help pinpoint exactly which part of the system is struggling.Continuous Testing and Iteration:
Scalability is not a “set it and forget it” task. As new features are added, or more users come on board, we need to revisit our performance tests to ensure that the new changes haven’t introduced any bottlenecks. Regularly scheduling load tests lets us adapt early, rather than waiting for issues to appear in production.
11. Document Rendering & Rich Text Editor
Designing the document rendering layer and the rich text editor is one of the most critical parts of building a system like Google Docs. At a high level, we want users to be able to see their documents in a visually accurate way—just as they would appear if printed or shared—and to edit those documents in a robust, intuitive manner. This section covers how to handle rich text formatting, how to choose a text editor engine or library, how to implement dynamic elements like tables and images, how to support drag-and-drop, how to handle exports, and how to integrate spell-check and multi-language capabilities.
11.1 Handling Rich Text Formatting (Bold, Italics, Lists, etc.)
When users apply formatting such as bold, italics, or lists, the editor needs to keep track of both the plain text and the formatting instructions that go along with it. One approach is to store formatting at the character or block level:
Character-Level Formatting: Each character (or range of characters) has associated properties like bold, italic, underline, or color. For example, we might have an internal data structure that says characters from index 10 to 15 are bold.
Block-Level Formatting: This refers to things like paragraphs, headings, and list items. For instance, a block might be marked as a bulleted list, numbered list, or heading level 1.
There are two main challenges here:
Keeping Rendering in Sync with Edits: Whenever a user types or changes formatting, the editor must re-render the affected portion of text without unnecessarily re-rendering the entire document. This requires an efficient update mechanism—often via a virtual DOM or a similar concept—so only the changed parts of the text are updated on the screen.
Preserving Formatting Across Complex Operations: If a user highlights text across different formatting blocks and applies a new format (like bold), the editor has to merge or split formatting segments properly. This can get more complicated when we combine nested formatting (e.g., bold + italic together).
11.2 Choosing Between contenteditable, Draft.js, Quill.js, or ProseMirror
Modern rich text editors can be built in several ways. A few popular approaches:
contenteditable (Native Browser Feature):
How it Works: We can make any HTML element editable by setting its contenteditable attribute to true. The browser will then allow direct editing within that element.
Pros: Easy to get started. Minimal overhead. Works out of the box for simple text styling.
Cons: Can become very complex to handle advanced features like collaboration, track changes, or consistent formatting across different browsers. Some default browser behaviour might conflict with our app’s desired behaviour.
Draft.js (by Facebook):
How it Works: Draft.js uses React for rendering and maintains an internal representation of the editor’s content as immutable data. We manage this data via callbacks and apply updates in a React-friendly way.
Pros: Well-suited for React applications, highly customizable. Good support for rich text features.
Cons: Requires careful state management. Might have a steeper learning curve for beginners.
Quill.js:
How it Works: Quill provides a WYSIWYG (What You See Is What You Get) editor out of the box. It’s built around a “delta” format for keeping track of changes.
Pros: Very easy to set up for common use cases. Has a modular architecture with ready-made themes and toolbars.
Cons: Might be harder to customize deeply if we have very unique formatting needs.
ProseMirror:
How it Works: ProseMirror uses a tree-structured document model. It is highly modular and can be extended to handle complex text structures, nested documents, and collaborative editing.
Pros: Excellent for building advanced editors with complete control over the document model. Good support for collaboration (e.g., with CRDTs or OT).
Cons: Higher learning curve. We need to understand ProseMirror’s concepts thoroughly to implement advanced features.
In a Google Docs-like application, we typically need a solution that supports real-time collaboration, complex formatting, and extensibility (tables, images, comments, etc.). Draft.js, Quill.js, and ProseMirror are more robust for that than raw contenteditable. If we’re comfortable with React and want a balance between customization and community support, Draft.js is a good fit. If we want the most flexibility and are okay with a more advanced library, ProseMirror is highly recommended.
11.3 Implementing Dynamic Tables, Images, and Embedded Elements
Documents often need more than just text. Tables, images, and embedded elements like videos or interactive components are essential in many use cases.
Tables: Implementing tables in a text editor can be done by treating each table cell as a mini-document area. For example, in ProseMirror or Draft.js, we could have a plugin or custom block type for tables. Each row and cell has structured data. The editor must allow adding new rows or columns, merging cells, and applying cell-level formatting.
Images: We can insert images either by providing a URL (e.g., from the web) or by uploading a file to our server. The editor then renders an <img> tag or a special component in the document. Typically, we also need to store some metadata (e.g., alt text, dimensions, alignment).
Embedded Elements (like videos, charts, or 3rd-party widgets): This is often referred to as “embedding” or “inserting an embed.” We might store these as special types of blocks or nodes in our editor’s data model. The rendering logic then detects that a block is a “video embed” or “chart embed” and renders the appropriate player or UI.
11.4 Enabling Drag-and-Drop for Images, Files, and Links
Drag-and-drop is a user-friendly way to add content to a document. When a user drags a file or an image onto the editor:
Detect the Drop: We might add an event listener (e.g., onDrop) that intercepts the dragged object when it’s dropped into the editor area.
Identify the File Type: Check if it’s an image, a document, or another file type.
Upload or Process: If it’s an image, we might upload it to our server or store it in a cloud storage bucket, then insert the resulting URL into the editor as an image node. If it’s a file, we might embed it as a link.
Insert into Document: Update our editor’s data model to reflect the newly inserted element. The view layer then re-renders to show it in the correct location.
11.5 Exporting Documents as PDFs or Word Files
Exporting is crucial for users who want to download a final version or share it outside the application. The process generally involves two steps:
Convert the Internal Document Model to a Standard Format: If we’ve chosen a library like ProseMirror or Draft.js, we will need a function that takes the internal representation and converts it to HTML or another intermediate format. This might include taking care of formatting details like bold, italics, headings, and lists.
Generate the Final File:
PDF Export: Commonly done by converting HTML (or a similar format) to PDF. Libraries like pdf-lib or pdfmake in JavaScript can help generate PDFs in the browser.
Word (DOC/DOCX) Export: This can be more complex, as Word has its own specific XML-based structure. We can either use a server-side approach (e.g., using a service that converts HTML to DOCX) or a client-side library that can generate DOCX files.
11.6 Implementing Spell Check and Grammar Suggestions
Spell check and grammar suggestions greatly enhance the user experience. There are a few ways to implement these features:
Browser’s Native Spell Check: Browsers have a built-in spell checker that can work with contenteditable fields. However, it may not provide grammar suggestions or advanced checks, and it can be inconsistent across browsers.
3rd-Party Services and APIs: We can send the text to a service like Grammarly or a self-hosted solution (e.g., LanguageTool) that returns spelling and grammar suggestions. We then highlight the areas in the editor and allow the user to apply or dismiss each suggestion.
Offline Dictionaries: For simpler use cases, we might include a dictionary in the client or in a service worker and compare each word the user types. Grammar checks, however, are more complex and typically require advanced language models or external APIs.
11.7 Multi-Language Support for Text Editing
In a globally distributed application like Google Docs, users may edit content in various languages within the same document. Handling multi-language support involves:
Character Encoding: Ensuring our application and database fully support Unicode so that characters from any language are stored and displayed correctly.
Input Method Editors (IME) Support: Certain languages like Chinese, Japanese, or Korean use an IME that converts typed phonetic characters into full words or phrases. The editor must handle this conversion process smoothly, ensuring partial inputs don’t break the text model.
Localized UI: In addition to text editing, the editor’s menus, toolbars, and dialogs should be translated into the user’s preferred language. This usually involves using a localization library (e.g., react-intl, i18next) to manage translations.
Spell Check in Multiple Languages: We might allow the user to switch or select the document’s language so that the spell checker or grammar checker knows which ruleset to apply. Some advanced systems can even handle multiple language segments in the same document.
A common beginner pitfall is not properly testing the editor with languages that have complex scripts (like Arabic or Hebrew, which are right-to-left) or with IME-based inputs. It’s important to thoroughly check all text editing flows to ensure a seamless experience across languages.
12. API Design & Communication
When building a real-time collaborative application like Google Docs, the way our frontend communicates with the backend is crucial. The frontend must send updates efficiently, receive changes in near real-time, and handle various network conditions. Below, we will explore different aspects of designing and optimizing these APIs, choosing the right communication strategy, ensuring performant responses, and implementing rate limiting.
12.1 Designing APIs for Saving and Fetching Documents
The core operations for a document editor revolve around two major tasks: saving user changes (such as text edits, formatting, or comments) and fetching the latest state of the document. A common pattern is to use RESTful HTTP APIs or GraphQL APIs to handle these operations in a structured manner.
When a user opens a document, the frontend typically sends an HTTP GET request to the backend to fetch the current state of that document. The server responds with the entire document (or a necessary portion of it) in a format like JSON. This initial load ensures the user has the most up-to-date version of the document.
For saving changes, the frontend needs to send updates whenever the user makes edits. Depending on our collaboration model, these changes might be sent:
Periodically (e.g., every few seconds or when the user pauses typing).
In real-time (immediately after each character input or operation).
It is essential to track partial edits on the client side to reduce network overhead. Instead of sending the entire document every time the user makes a small change, we can send only the “diff” or the “delta” that represents the user’s edits. For example, if the user types two letters in a large document, it is more efficient to send just those two letters along with information about where they were inserted rather than re-sending the entire file. This concept is especially important for supporting multiple concurrent collaborators without overwhelming the server.
On the server side, these “diffs” or “deltas” are combined and stored in a versioned manner. Many real-time collaborative solutions use techniques like Operational Transformations (OT) or Conflict-free Replicated Data Types (CRDTs) to handle conflicts elegantly. Even if our frontend focuses on simpler solutions, designing our APIs to support partial updates ensures minimal bandwidth usage and quicker response times.
12.2 Choosing Between WebSockets, WebRTC, and Polling
Once we have a way to fetch and save documents, we must also consider how to deliver real-time updates to all collaborating users. There are several communication patterns to choose from:
WebSockets: These provide a full-duplex channel (meaning the server and client can send messages to each other at any time) over a single TCP connection. For Google Docs–style applications, WebSockets are often the default choice because they enable instantaneous broadcasts of changes to all connected clients. When one user types, a small message containing the change is sent through the WebSocket to the server, which then forwards it to other users.
WebRTC: This is commonly used for peer-to-peer communication (e.g., audio/video calls) and might not be the first choice for text collaboration. While it can reduce server load by sending data directly between clients, it also introduces complexities in managing multiple connections (especially as more collaborators join). Typically, WebRTC is not the primary mechanism for text-based collaboration unless we specifically need peer-to-peer file sharing or streaming.
Polling (Long or Short Polling): Polling means the client repeatedly asks the server if there are any updates. With short polling, the client might send a request every few seconds. With long polling, the server holds the connection open until an update is available, then responds and the client immediately re-establishes another long poll. Polling is simpler to implement than WebSockets but is less efficient for high-frequency or large-scale real-time editing. It can also increase server load since many requests are made, even if no changes occur.
For a Google Docs–like system, WebSockets are typically the most suitable because they provide reliable, near-instant updates with less overhead compared to constant polling. Polling might be used as a fallback mechanism if WebSockets are unavailable or blocked by certain networks. WebRTC may be valuable for specific features (like live audio chat within the document), but it is not the go-to solution for text synchronization.
12.3 Optimizing API Responses for Performance
API performance is critical for a fast and seamless user experience. In a collaborative editor, there can be a large number of requests happening simultaneously as users type, format text, or insert media. Several strategies ensure the frontend receives responses quickly:
Efficient Payloads: Rather than sending the entire document, only send the necessary pieces of data. If a single paragraph is updated, respond with that paragraph or a small “diff” rather than an entire 20-page document.
Compression: Use gzip or Brotli compression on the server to reduce the size of the response. Smaller payloads result in faster transfers, especially when users have slower network connections.
Pagination or Chunking: For especially large documents, consider chunking data. Fetch only the visible sections of the document (e.g., if the user is on page 3, initially load pages 2–4). When the user scrolls, more chunks can be requested. This approach is often combined with virtualization on the frontend, so the application only renders what is visible on the screen.
Caching & Conditional Requests: Implement caching headers (e.g., ETag, Last-Modified) so the client can fetch only what has changed. This approach significantly reduces server load and makes responses faster.
Load Balancing & Horizontal Scaling: If the server becomes overloaded by too many simultaneous requests, use load balancing to distribute incoming connections across multiple servers. This ensures no single server becomes a bottleneck.
By focusing on sending only the essential data and using techniques like compression and caching, we can make sure that each API call completes as quickly as possible. This speed is particularly important when we are dealing with real-time collaboration and want to minimize lag between user edits and visible updates.
12.4 Implementing Rate Limiting for API Calls
Rate limiting prevents any single client (or a group of clients) from overwhelming the server with excessive requests. In a real-time editor, it is possible for a large team to generate a high volume of updates if multiple users type simultaneously or if malicious scripts attempt to flood the server.
A common approach to rate limiting is to set a threshold for the number of requests a client can make in a given time window (e.g., 100 requests per minute). If the client exceeds this threshold, the server temporarily blocks or delays further requests. The exact numbers will vary based on the system capacity and the typical editing patterns in our application.
There are several techniques and algorithms to implement rate limiting effectively:
Token Bucket: Each user is given a “bucket” of tokens that refill at a certain rate. Each request costs one token. If the bucket is empty, further requests are denied or queued.
Leaky Bucket: Works similarly to the Token Bucket but focuses on processing requests at a fixed rate, discarding or delaying requests if the capacity is exceeded.
Fixed Window: Count how many requests each user makes per time window (e.g., 1 minute). If the user hits the limit, deny further requests until the next time window starts.
For a Google Docs–type system, we might not want to block users after a few too many requests since legitimate bursts of activity can happen (imagine multiple users actively typing). Instead, it’s common to use “soft limits” that slow down request processing or gracefully degrade certain features rather than outright denying them. For instance, we might queue non-essential requests (like auto-saving certain analytics data) but always accept crucial operations (like text edits).
In practice, implementing rate limiting involves both server-side and client-side logic. On the server side, track the user’s request counts, enforce limits, and send back specific error codes (e.g., HTTP 429 Too Many Requests) when the limit is exceeded. On the client side, we can respect these server responses by either waiting for a retry-after period or informing the user if their actions are temporarily limited.
By combining well-structured APIs, a real-time communication channel (preferably WebSockets), optimizations for payloads and data transfer, and robust rate limiting, we ensure that our document editor remains both responsive and scalable, providing a smooth collaborative experience for users of all skill levels.
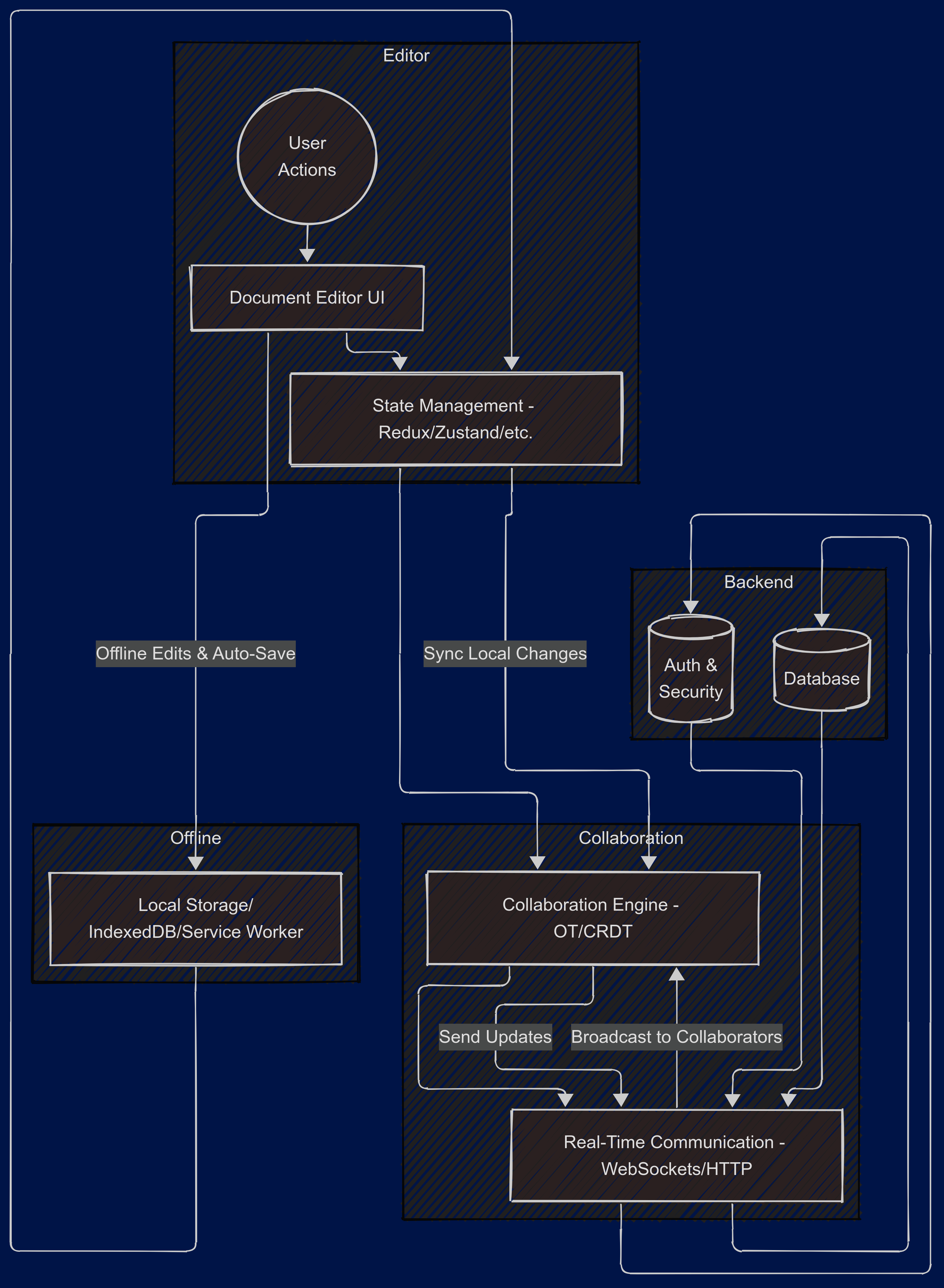
13. Testing & Debugging
13.1 Performance Testing for Real-Time Collaboration
When we have multiple users editing a document at the same time, the system needs to respond quickly and handle all these simultaneous edits smoothly. That’s where performance testing comes in.
What Is Performance Testing?
Performance testing helps us see if our application can handle many users typing, editing, and communicating at once—without slowing down or crashing.Key Metrics to Look At
Latency (Delay): How quickly do changes show up for other collaborators?
Throughput: How many edits can the system handle in a given time (like edits per second)?
Resource Usage: How much memory and CPU does the application consume when many users are connected?
How to Conduct Performance Tests
Simulate Real-World Usage: Use tools (e.g., JMeter, Locust, or custom scripts) to simulate hundreds or thousands of users editing simultaneously.
Measure Response Times: Track how fast edits appear on other users’ screens.
Test Different Network Conditions: Simulate slower networks or intermittent connections to see if the app degrades gracefully (e.g., tries to reconnect or caches changes offline).
Load Testing & Stress Testing: Gradually increase the number of simulated users (load testing) and push the system to its limits (stress testing) to find breaking points.
Why It Matters
Effective performance testing ensures that real-time collaboration remains smooth even under heavy loads. If the system lags, users lose trust. Early detection of performance issues prevents frustrated users and costly outages.
13.2 Writing Unit, Integration, and End-to-End Tests
Testing our code isn’t just about finding bugs; it’s also about ensuring the pieces of our application work well together. Here’s a breakdown of different test types and why each one is important.
Unit Tests
Definition: Tests that focus on one tiny part of our code—like a single function or component—without involving any external system.
Example: We might test a function that handles user input (e.g., a function that formats text or updates the cursor position).
Benefits: Quick to run, easy to maintain, and they help catch errors early before they affect other parts of the application.
Integration Tests
Definition: Tests that check if different parts of our system work together correctly.
Example: We might test how the text-editing component interacts with the real-time synchronization engine.
Benefits: Ensures that data flows properly between components. For instance, when a user types text, the real-time engine should immediately broadcast that change to others.
End-to-End (E2E) Tests
Definition: Tests that simulate a user’s journey through the entire system—from the user interface to the server and back.
Example: We might automate a browser to open a document, type some text, and confirm that another user sees the updates in real time.
Benefits: Validates the entire flow of the application. If something breaks at any point (UI, server, or database), E2E tests can catch it.
Tools and Best Practices
Common testing tools: Jest, Mocha, Cypress, or Playwright.
Keep tests maintainable by writing clear test cases that describe what they are testing.
Mock external services (like network calls) so we don’t have to rely on a real server for every test.
13.3 Debugging Issues in Real-Time Syncing and Conflict Resolution
Real-time applications can be tricky to debug because problems often happen only when multiple users are editing simultaneously. Here’s how to approach debugging:
Identify the Scope of the Problem
Is the issue happening only when multiple users type in the same area, or does it happen whenever new users join?
Is the conflict a data synchronization problem or a UI rendering issue?
Use Clear Logging and Alerts
Print out detailed logs whenever users make edits (e.g., “User A inserted text at position X”).
If two edits happen at the same exact time, logs can help us see the order in which our system processed those edits.
Simulate Edge Cases
Simulate Slow or Lost Connections: Disconnect and reconnect users during editing. Check how the system merges changes.
Simulate Version Mismatch: Intentionally keep one user’s document version behind and see if the system properly merges changes once reconnected.
Conflict Resolution Strategies
If using Operational Transformations (OT) or CRDTs, they are designed to handle conflicts automatically. However, if we find mismatches (like text duplication or missing pieces), look for errors in the transformation logic.
Ensure we’re handling the ordering of events correctly. Even a small timing bug can cause confusion in the shared document state.
Step-by-Step Reproduction
Narrow down the steps that lead to the bug (e.g., “User 1 selects text and types X, at the same time User 2 deletes that text”).
Once we can reproduce consistently, use debugging tools (browser dev tools or specialized logging) to inspect data structures in real time.
13.4 Logging and Monitoring User Actions for Debugging
Logging and monitoring are crucial for understanding what happened in our system at any point in time, especially when things go wrong or conflict resolutions fail.
Why Log and Monitor?
Trace User Actions: If a user’s document looks corrupted, logs can show a chronological history of edits.
Identify Patterns: If we see many errors happening under similar conditions, we can target our fixes more effectively.
What to Log?
Key Events: User login, document load, edits (insertions, deletions), role changes (e.g., from viewer to editor).
Collaboration Events: Connection drop, reconnection attempts, merges of offline changes.
System Data: Timestamps, user IDs (or session IDs), document IDs, and any error messages.
How to Implement Logging
Frontend Logging: Use the browser’s console for real-time feedback, but also send critical events to a monitoring service.
Monitoring Services: Tools like Sentry, Datadog, or LogRocket can capture logs, user actions, and error traces in a central location.
Privacy Considerations: Make sure not to log sensitive data (like personal information or entire text content). Anonymise or encrypt where necessary.
Real-Time Dashboards and Alerts
It’s helpful to have a real-time dashboard showing user activity and error rates. If the error rate spikes, our team can investigate immediately.
Alerts can be configured (e.g., via email or Slack) so we know when something unusual happens (like a sudden jump in error logs).
Continuous Improvement
Each error log or bug report is an opportunity to learn. Regularly review logs to find recurring issues or performance bottlenecks.
Update our logging strategy as our application grows. For instance, if we add new features, ensure we log the relevant events for them.
14. Trade-offs & Design Decisions
Designing a collaborative document editing application like Google Docs requires making careful decisions about how the frontend should communicate with the backend and how much logic should reside on the client (in the browser) versus on the server. Below, we explore four key areas where trade-offs often come into play.
14.1 Choosing Between a Client-Heavy vs. Server-Heavy Architecture
When we talk about a client-heavy (or “thick client”) architecture, it means that most of the application logic, including state management, text-processing algorithms, and collaboration logic, runs in the user’s browser. By contrast, a server-heavy (or “thin client”) architecture places most of this logic on the server, and the browser just renders the results.
Client-Heavy Architecture
Pros
Better Responsiveness: Users experience less delay because many actions (like formatting text or cursor movement) happen instantly in the browser without waiting for the server.
Reduced Server Load: Because the client handles a lot of the processing, servers don’t have to handle every tiny change. This can lower hosting costs or allow for greater scalability.
Offline Support: The client can store significant parts of the application logic and data locally (e.g., using IndexedDB or Service Workers), making it easier to add offline editing capabilities.
Cons
Complexity on the Frontend: Building and maintaining a complex editor with real-time collaboration in the browser can be challenging, requiring advanced JavaScript/TypeScript skills and careful architecture.
Initial Load Times: If the client app is large, it might take longer to load initially because the browser needs to download, parse, and run a lot of JavaScript.
Hardware Dependencies: Users with older devices or slow browsers may experience performance problems if too much processing happens locally.
Server-Heavy Architecture
Pros
Simplicity for the Client: The browser can be simpler—often just a display layer. This can lead to smaller bundle sizes and potentially faster startup times.
Centralised Logic: All core collaboration, transformation, and synchronization logic live on the server, which can simplify debugging since most logic is in one place.
Cons
Higher Server Costs: The server must handle the majority of document processing. This can become expensive and more complex to scale.
Increased Latency: Every action (like typing a character) requires a trip to the server and back for processing. This can result in slower user experiences, especially in real-time applications.
Offline Mode Challenges: Supporting offline editing is much harder because the server is responsible for most logic. When the user goes offline, the entire editing flow may be disrupted.
Most modern collaborative editors, including Google Docs, adopt a mostly client-heavy approach for responsiveness and scalability. The server is still crucial for handling syncing logic, storing canonical data, and providing real-time updates, but the client does the heavy lifting of rendering and immediate text editing.
14.2 Comparing WebSockets, WebRTC, and Polling for Real-Time Communication
Real-time communication is the backbone of collaborative editing. There are three main ways to implement real-time features:
WebSockets
WebRTC
HTTP Polling (or Long Polling)
1. WebSockets
WebSockets provide a persistent, full-duplex communication channel over a single TCP connection. Once established, the connection stays open, allowing the server and client to send data back and forth freely.
Pros
Low Latency: Changes appear quickly for all collaborators.
Bidirectional: The server can push updates to clients instantly, and clients can send updates without opening new requests.
Resource Efficient: Compared to constant polling, WebSockets are efficient because they don’t require re-establishing a connection repeatedly.
Cons
Server Complexity: Managing and scaling large numbers of open WebSocket connections can be more complex.
Browser Support: While widely supported now, some very old browsers may not support it.
Given these pros and cons, WebSockets are often the go-to solution for real-time collaborative applications.
2. WebRTC
WebRTC (Web Real-Time Communication) is typically used for peer-to-peer connections, especially in audio/video streaming. It can also be used for data channels, but it’s more complex to set up and maintain for multi-user text editing.
Pros
Peer-to-Peer: Can reduce server bandwidth usage if data is sent directly between clients.
Good for Multimedia: Ideal for video/audio calls or screen sharing.
Cons
Complex to Implement: Setting up signaling servers and dealing with NAT traversal can be challenging.
Less Common for Text Collaboration: Most text-based collaboration uses a central server for conflict resolution.
While WebRTC can be an interesting choice for certain use cases, WebSockets are generally simpler and more reliable for real-time text collaboration with multiple users.
3. HTTP Polling (or Long Polling)
HTTP polling involves the client repeatedly sending requests to the server at regular intervals (e.g., every few seconds) to check for updates. Long polling involves holding the request open until an update arrives.
Pros
Wide Compatibility: Works on virtually any browser or device, with no special protocol.
Easy to Implement: It’s just making HTTP requests on an interval or waiting on an open request.
Cons
Higher Latency: Users might see updates only after a polling interval, making the experience less real-time.
Inefficient: Constant polling can waste bandwidth if updates are infrequent.
Server Load: Servers have to deal with repeated requests, which can add overhead.
14.3 Trade-offs Between Performance and Consistency
When multiple users are editing the same document, we need to consider how to keep everyone’s views of the document consistent while also maintaining fast performance.
Strong Consistency: Ensures that every user sees the exact same document state at all times. This often requires locking certain parts of the document or using advanced algorithms (like Operational Transformations or CRDTs).
Advantage: Fewer conflicts and confusion for users because the document never diverges.
Drawback: More complicated to implement. Certain edits may be temporarily blocked, and there can be higher latency while resolving conflicts.
Eventual Consistency: Allows small temporary differences in each user’s view, but eventually, all changes converge to the same state.
Advantage: Generally lower latency and simpler user experience since everyone can type freely.
Drawback: Might see short-lived conflicts or “jumps” in the text before the system resolves them.
Google Docs uses a system closer to eventual consistency but employs sophisticated algorithms to ensure changes converge quickly and predictably. This approach balances a smooth user experience (performance) with the need for accurate shared state (consistency).
14.4 Handling Graceful Degradation in Case of WebSocket Failures
Even though WebSockets are ideal for real-time updates, there could be situations where the connection fails or the user’s network blocks WebSockets. A well-designed editor should degrade gracefully:
Fallback to Polling: If the client can’t establish a WebSocket connection, it could switch to an HTTP polling mechanism. This ensures the user can still edit and receive updates, albeit with a slight delay.
Local Queuing of Changes: If the user temporarily cannot communicate with the server (for example, due to an offline scenario or a blocked connection), the editor should store changes locally. Once a connection (WebSocket or otherwise) is restored, it can sync these changes.
User Notifications: If real-time features are partially unavailable, informing the user (e.g., showing an icon or a warning message) helps set expectations. They’ll know collaboration may be slower or temporarily offline.
15. Future Enhancements & Innovations
Thinking about the future of a platform like Google Docs involves looking at ways to make the user experience more intuitive, powerful, and flexible. Below are some forward-looking ideas and how we might implement them in a robust document-editing application.
15.1 AI-Powered Writing Assistants (Like Grammarly)
Imagine as we type, a smart helper provides real-time feedback on our writing. These suggestions could include grammar corrections, style improvements, and even context-based recommendations, like changing our tone if we’re writing a formal letter or simplifying complex sentences for a younger audience.
To achieve this, we can integrate an AI service (either built in-house or through third-party APIs) that analyzes the text as users type. Whenever new text is added or existing text is modified, the frontend sends small chunks of data (like sentences or paragraphs) to the AI service. The AI returns suggestions or corrections almost instantly, which the editor displays to the user.
Users can choose to accept or reject these suggestions, similar to how “Track Changes” or spell-checkers work. The implementation might look like this in the frontend:
Text Hook: Each time the user types, an “onChange” event captures the updated text.
API Call: The new text or the changed portion is sent to an AI endpoint, which processes it for grammar, style, and clarity.
Suggestions Display: The AI’s feedback is then displayed inline (e.g., red underlines for spelling, blue for grammar, etc.). Hovering or clicking on these underlines shows suggested corrections.
User Interaction: The user can accept the suggestion (the text updates automatically) or ignore it, ensuring they have full control over the edits.
Over time, the AI can also learn from user behavior. If the user consistently ignores certain types of corrections, the AI might adapt its recommendations accordingly. This personalization adds even more value to the writing assistant.
15.2 Voice-to-Text and Handwriting Recognition
Another exciting area is making the editor accessible to people who prefer or need alternative input methods, such as voice or handwriting. In some situations—like taking notes in a class or a meeting—typing may not be the most convenient option. Similarly, accessibility features are crucial for users with disabilities or those who simply find voice dictation more efficient.
Voice-to-Text can be integrated using APIs like the Web Speech API (in modern browsers) or a specialized service (such as Google Cloud Speech-to-Text). The user would click a “microphone” icon and start dictating, while the system captures the audio, converts it into text, and inserts it into the document in real time. We would need to handle different languages, accents, and background noise. Also, having an “edit” or “command” mode could help users indicate punctuation or formatting through voice commands (e.g., saying “new line” or “bold this word”).
Handwriting Recognition might use a stylus or touchscreen input. Users could write on a canvas-like area within the editor, and the system would convert the handwritten notes into typed text. Libraries exist for recognizing handwritten characters, often using machine learning models that run either locally or in the cloud. The main challenge is accurately converting handwritten shapes into characters and dealing with different handwriting styles. Over time, the recognition engine can improve by learning from user corrections, leading to more accurate conversions.
15.3 Embedding Third-Party Apps and Plugins
Collaboration platforms become extremely powerful when they allow other developers or companies to integrate their tools directly. This means users can enrich their documents with features that the core editor might not provide. For example, a project management plugin could insert live-updating task lists, or an educational plugin could add interactive quizzes right inside the document.
To enable this, the platform would offer a plugin framework or SDK (Software Development Kit). The framework would define how plugins can:
Access Document Data: Plugins might be able to read or modify document content (with user permission).
Add UI Components: Plugins might insert their own buttons in the toolbar or panels within the editor interface.
Handle Events: Plugins could listen for events (like text changes or cursor movements) to provide real-time interactions.
Security is crucial here. Each plugin must be sandboxed so it can’t compromise users’ data or privacy. Typically, we’d run plugins in an isolated iframe or use a strict permissions system to limit what they can do. This approach ensures that even if a plugin malfunctions or has malicious code, it can’t affect the broader application or other documents.
15.4 Custom Themes and User Personalization
Finally, giving users the freedom to change the way their editor looks and behaves can make a huge difference in how comfortable they feel using it every day. Some people might want a dark theme for late-night work, while others may prefer larger fonts or a colorful interface. Personalisation also extends to configuring keyboard shortcuts, deciding which toolbars are visible, or having quick-access buttons for frequently used features.
In the frontend, we can achieve customizable themes by applying different CSS variables or classes that define colour schemes, spacing, and font choices. When the user selects a theme, the application updates these variables, instantly changing the look and feel without reloading the page. We can store user preferences in their account settings (on the server) or locally (in IndexedDB or localStorage) so that each time they open the editor, their preferred theme and settings are automatically applied.
Beyond simple theme changes, advanced personalization could include user-defined macros or templates. For instance, if a writer frequently uses a specific document format, they could create a saved layout that includes pre-styled headers, footers, and boilerplate text. Every time they start a new document with that template, it comes pre-filled with the elements they need, saving time and maintaining consistency.
16. Conclusion
Designing a frontend system for a platform like Google Docs involves much more than just creating a simple text editor. At its core, we need to handle real-time collaboration, where multiple users can see each other’s updates almost instantly. This requires careful planning of data flow, state management, and how changes are broadcasted or received by all participants. We explored the idea of using concepts like Operational Transformations (OT) or Conflict-free Replicated Data Types (CRDTs) to resolve editing conflicts in a way that feels seamless to everyone involved.
We also examined the importance of performance, which can be a major challenge when editing large documents or displaying many pages at once. Strategies such as virtualizing the view (only rendering what is on the screen), caching data locally (for example, using IndexedDB), and optimizing the rendering pipeline can dramatically improve the user experience. On the collaboration side, we highlighted features like track changes, commenting systems, and real-time presence indicators (showing cursors and selections) that are essential to an online document editor.
Security and access control are equally critical in a system handling sensitive user data. We must protect against common threats like XSS (Cross-Site Scripting) and CSRF (Cross-Site Request Forgery), while also enabling role-based permissions. The entire system should be designed to safeguard data both in transit and at rest, often involving encryption and safe coding practices.